LangSmith Engine自动化关闭代理调试循环,多模型企业仍需中立层

企业在构建和部署AI代理时面临一个痛点:工程师往往需要花费大量时间才能发现代理的错误,调试循环持续不断,尤其是在缺乏人工干预的情况下问题更为突出。
LangChain旗下的监控与评估平台LangSmith近日推出了一项公共测试版新功能,有望缓解这一难题。该功能名为LangSmith Engine,可自动化整个链条——通过检测生产故障、诊断根源代码、起草修复方案并防止回归,在单次自动化流程中完成所有步骤。
LangSmith Engine为AI工程师提供了更快的排查路径,但该产品进入的是一个竞争激烈的市场:Anthropic、OpenAI和Google等厂商正将可观测性与评估功能整合至自身平台。
LangSmith Engine如何解决故障
LangChain在博客中提到,典型的代理开发周期始于追踪代理行为以理解其运作,随后识别漏洞,调整提示词和工具,并创建基线数据集。开发者随后运行实验、检查回归问题,最终部署代理。
问题在于,当追踪审查无法暴露故障模式、错误重复难以察觉,且缺乏针对性评估工具时,用户常会遇到问题。当这些问题在生产环境中重复出现时,企业往往束手无策。
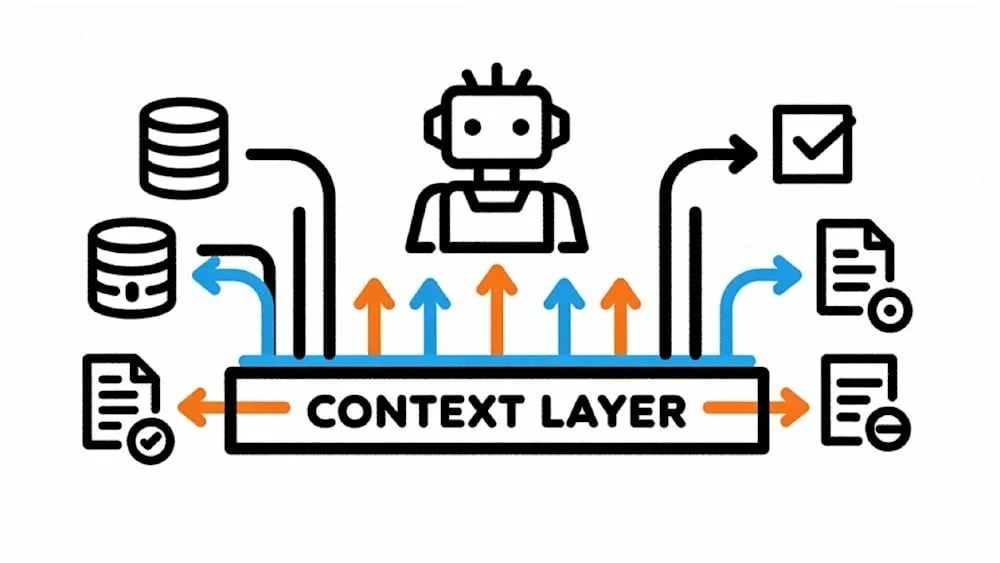
根据博客内容,LangSmith Engine通过监控生产轨迹,检测多种信号类型,包括“显式错误、在线评估失败、轨迹异常、负面用户反馈以及用户询问代理未设计回答的问题等异常行为”。
随后,该工具会读取实时代码库,定位问题根源并起草拉取请求,同时针对特定故障模式提出自定义评估方案。人类工程师仅在审批环节介入。
该功能基于LangSmith现有的追踪和评估基础设施,并与企业现有的评估结果兼容。
与Weights & Biases、Arize Phoenix和Honeyhive等可观测性工具不同,LangSmith Engine可自动完成整个链条——从检测故障到诊断根源再到起草修复方案,仅在审批阶段引入人工干预。
模型提供商的评估工具整合趋势
尽管LangSmith识别出许多企业对评估循环的需求,但Engine的推出恰逢大型模型提供商开始在其平台内提供可观测性工具的时期。这意味着企业可能选择使用端到端平台,而非将LangSmith Engine添加至现有工作流。
Anthropic的Claude Managed Agents将代理部署、评估与编排整合为单一套件;OpenAI的Frontier则为构建、治理和评估企业代理提供类似端到端平台——不过两者均面临企业对单一供应商承诺的担忧。
然而,从业者指出,并非所有企业希望将评估和可观测性完全整合至单一平台。
Workwise Solutions创始人兼首席顾问Leigh Coney告诉VentureBeat,第三方可观测性是许多企业的默认选择。
“我合作的基金机构使用Claude进行分析,同时用GPT处理另一项工作流。若可观测性存在于每个提供商的工具中,就会形成两个无法互通的系统。合规团队无法生成统一的审计记录,”他说,“因此第三方可观测性得以存续,因为多模型已是企业的默认配置,必须有人站在提供商之间。”
True Fit首席执行官兼联合创始人Jessica Arredondo Murphy表示,LangSmith等独立平台需向企业证明,能否“回答长期问题:是否成为跨模型的质量与可靠性操作层”。
“企业并未如模型提供商所愿迅速整合至第一方工具。我观察到的是务实的分裂:团队会使用第一方工具实现快速上手和早期调试,但一旦关注生产可靠性、治理和长期灵活性,他们倾向于引入更中立的可观测性与评估层。”她补充道。
LangSmith Engine现已开放公共测试版。团队可连接追踪项目,选择性关联仓库,Engine将自动从生产轨迹中提取问题。
关注微信号:智享开源 ,可及时获取信息




 关注微信
关注微信

还没有任何评论,你来说两句吧!